Unit testing
The naive way to write software is to plan for the best of all possible worlds where nothing ever goes wrong. One of the best reality checks for that approach is exposing code to users who invariably behave in ways that seem completely incomprehensible to the developer. It then becomes suddenly clear that there are many more checks that need to be done, exceptions to be handled and orientation to be provided if the software is going to perform its function successfully. The best-case, optimistic route through the software is sometimes called the happy path. Focusing exclusively on the happy path in testing means that many potential errors will be overlooked.

The software engineer is responsible for ensuring that the code they produce is as robust as possible. That level of quality follows partly from a principled approach to software design. However, that is not enough to ensure that the code will work under all possible input conditions. The only way to have confidence that it will do so is to test it thoroughly through unit tests. These are so called because they are supposed to test the code at the unit level - that is, the level of the individual method (or function) where the functionality cannot be broken down any further. The idea is that the smaller and simpler a piece of code it, the easier it is to verify that it works correctly through unit testing. That is because each corresponding test will be simple and easy to understand. Unit tests can be run manually, but a better way is to take advantage of modern tools that allow you to automate your tests. They can then be managed along with the rest of the codebase and can be run repeatedly by any member of the development team.
Anatomy of a unit test
The overall process of carrying out a unit test is visualised in Fig. 1.
flowchart LR
node1([1. Setup testing context]) --> Test
subgraph Test
node2([2a. Define expected result]) --> node3([2b. Call the method])
node3 --> node4([2c. Test assertion])
end
Test --> node5([3. Teardown testing context])
Fig. 1: Unit test structure
1. Setup
Most methods rely on data provided by other parts of the application to provide the context in which they run. However, the point of a unit test is to test the unit in isolation, and to do that, the first stage in the process has to be to create a realistic working context. This can involve
- loading a database with a specific known set of data
- erasing a hard disk and installing a known clean operating system installation
- copying a specific known set of files
- the preparation of input data as well as set-up and creation of mock objects
A mock object is something that is created purely for the purposes of the test to simulate the existence of a real software object. For example, if the software under test was a bus tracker application it would receive its data from the bus company’s API. Certain functions would only be triggered for certain combinations of API data. To avoid the need to wait for such conditions to appear naturally, a mock API could be used that was specifically designed to deliver the required data continuously or at regular intervals. The following terms define slightly different temporary objects for testing:
Fake: A fake is a generic term that can be used to describe either a stub or a mock object. Whether it’s a stub or a mock depends on the context in which it’s used. So in other words, a fake can be a stub or a mock.
Mock: A mock object is a fake object in the system that decides whether or not a unit test has passed or failed. A mock starts out as a Fake until it’s asserted against.
Stub: A stub is a controllable replacement for an existing dependency (or collaborator) in the system. By using a stub, you can test your code without dealing with the dependency directly. By default, a stub starts out as a fake.
2a. Define expected result
A unit test implements a test case which maps known inputs to a known output. These known values are defined at the start of the test.
2b. Call the method
The method is called with the defined arguments and the result is captured in a variable.
2c. Test assertion
An assertion is essentially a test carried out on the result returned by the method under
test. Unit testing frameworks provides various types of assertion statement, but the most
common is the assertion of equality between the returned value and the expected value.
The example C# code in Fig. 2 illustrates the use of the Assert.AreEqual() test.
using Microsoft.VisualStudio.TestTools.UnitTesting;
using System.IO;
using System;
namespace HelloWorldTests
{
[TestClass]
public class UnitTest1
{
private const string Expected = "Hello World!";
[TestMethod]
public void TestMethod1()
{
using (var sw = new StringWriter())
{
Console.SetOut(sw);
HelloWorld.Program.Main();
var result = sw.ToString().Trim();
Assert.AreEqual(Expected, result);
}
}
}
}
Fig. 2: Example unit test in C#
Notes
Line 1: Unit testing functions are defined in the Microsoft.VisualStudio.TestTools.UnitTesting namespace.
Line 7: This annotation is required when using MSTest in Visual Studio.
Line 10: This line defines the expected output
Line 11: This annotation is required by MSTest
Lines 17 & 19: The method under test is called and the output captured in the
resultvariable.Line 20: An assertion is used to test whether the expected and actual values are the same.
3. Teardown
After the test has been run, any fixtures that were created in the first stage need to be
removed. This process is commonly called teardown, although some frameworks use different
terminology. MSTest, for example, uses assembly and cleanup instead of setup and
teardown.
Good practice for unit tests
Test names
The clean code practice of using clear an unambiguous names for tests is very
useful here - it helps to identify exactly what has gone wrong if a test fails. For example,
we could imagine calling the maximum value test something like TestMaxBasketValue() and
for a while, we might remember what that meant. Once it was just ine test among hundreds,
it would help to give it a more descriptive name such as
TestBasketValueDoesNotExceedMaxValueLimit(). The inconvenience of typing in a long name
(once), is easily outweighed by the way it explains what has gone wrong when the test
fails unexpectedly.
Microsoft recommends that test names should have three parts:
- The name of the method being tested.
- The scenario under which it’s being tested.
- The expected behaviour when the scenario is invoked.
Avoid using magic strings
A magic string is a hard-coded literal used with no explanation. The problem with them is that they fail to communicate what the test is trying to achieve. If another developer has to spend valuable time working out what the test is doing, it is not well-written.
KISS
Unit tests should test one thing in a simple manner. That means keeping the number of assertions to a minimum - ideally just one - and avoiding complex control structures such as loops and conditionals.
Unit test value
Units tests accumulate over time and the theory is that they can be run by the whole development team on a regular basis. The test suite therefore provides continuous protection against faulty code. It isnot beneficial to test absolutely every line of code in the system. Including trivial tests can be a wwaste of time. Instead, they should focus on delivering maximum value for the minimum overhead. The value of unit tests is captured in four pillars by Khorikov, 2020:
-
Protection against regressions
Exercising more code in a single test maximises the possibility of finding regression errors.
-
Resistance to refactoring
Tests should focus on behaviour and not implementation
-
Fast feedback
Tests should run quickly - if tests run slowly, developers may avoid them
-
Maintainability
Tests should be simpleand easy to understand. They should also be easy to run.
Leaving aside maintainability for the time being, the ideal test should be ine that maximises the other three pillars simultaneously - that would be the three-way intersection in Fig. 3.
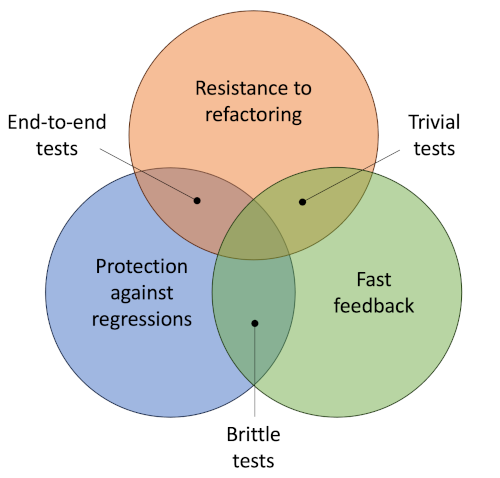
End-to-end tests are designed to test the system from the user’s point of view. They focus on high-level behaviours and exercise a lot of code at one time. For these reasons, they deliver high value on two counts, but because they use a lot of the system functionality, they can be comparatively slow.
Trivial tests focus on individual operations in the code and are therefore resistant to refactoring and they are fast. On the other hand, because they do not exercise much code they are unlikely to identify regression errors. As the name suggests, this type of test is probably not worth the additional overhead.
Brittle tests are those which are closely tied to the underlying implementation. They run fast and they will definitely guard against regression errors. However, because they use implementation detail, they are not very resistant to refactoring.
Khorikov recommends maximising a test’s resistance to refactoring as the priority, and then choosing which of regression protection and speed is the most desirable quality in the particular case. This comes down to eliminating brittleness wherever possible.
How many unit tests?
A typical method will have an acceptable range of inputs depending on its parameters, and an acceptable range of outputs. The ideal unit test would ensure that the code produces expected output for every possible combination of parameter values. This is not always possible, however, because integer parameters, for example, have a theoretically infinite range. In practice, it is more feasible to concentrate on typical and boundary cases. Typical values correspond to the happy path where everything works as planned, and the boundary (or edge) cases represent the extreme or exceptional values that parameters might take. A good example of an exceptional value would be where the argument has not been correctly set and the parameter therefore has a null value. The number of tests required therefore increases with the number of parameters.
When the method is implementing an explicit behaviour, there may be specific checks that can be carried out and these checks could also be captured in unit tests. For example, the method might be part of an ecommerce system which has a limit on the total cost of an order. One or more unit tests could be used to ensure that the value limit is never exceeded as items are added to the shopping basket. The general point is that a single method is likely to have several associated unit tests.
Testing private elements
The purpose of unit testing should be to verify that the system behaves as expected. How that behaviour is implemented should be irrelevant. For that reason, many testing frameworks only allow tests to be applied to publicly exposed methods and properties.
This is easy to understand from the point of view of eliminating test brittleness which arises from tying tests too closely to the underlying implementation detail. If a private element is important, then its effect should be observable in the result of calling a public method or in the value of a public property.
While there may be exceptions (see Khorikov (2020) Ch. 11), the general strategy should be to avoid testing private elements.
Further reading
- Software Testing (O’Regen, 2022, Ch. 8)
- Unit testing : principles, practices, and patterns Khorikov, 2020
- Unit testing best practices with .NET Core and .NET Standard