Maintenance/evolution
Software evolution refers to the process of continuously adapting and improving software systems to meet changing requirements, rectify faults, and enhance performance and reliability. It is an essential aspect of software engineering, acknowledging that software systems must evolve to remain useful and effective in dynamic business environments. The importance of software evolution lies in its ability to sustain the value of software assets over time, ensuring they can adapt to new technological advancements, changing user needs, and evolving business processes. By systematically managing and implementing changes, organisations can extend the lifespan of their software, reduce the costs associated with system failures, and maintain a competitive edge through enhanced functionality and performance. Without ongoing evolution, software systems become obsolete, less efficient, and increasingly challenging to maintain, ultimately risking significant disruptions to business operations.
The concept of software evolution comes from the structured development tradition where the software development lifecycle is usually expressed in terms of phases as shown in Fig. 1. Each phase builds on the previous one, culminating in the maintenance phase in which the project team has been disbanded and the system is in active use supported by a maintenance team.
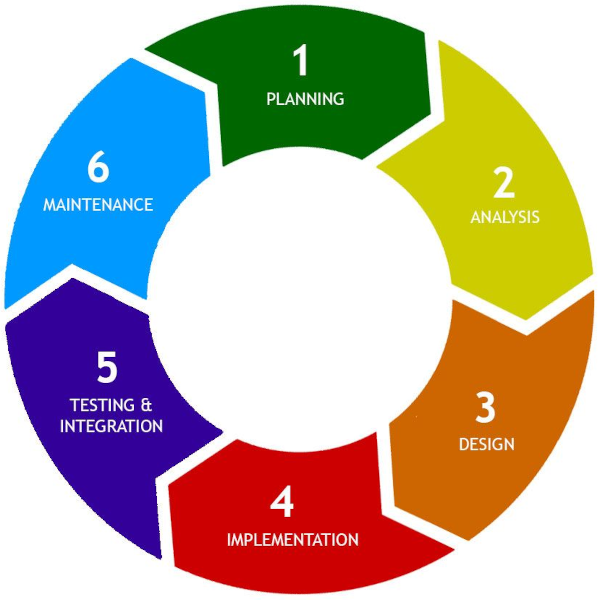
Although we are more used to thinking about software development in terms of an iterative Agile cycle, even in Agile projects there has to be an initial development effort that leads up to the initial release and deployment of the application. After that, the system is in active use and changes have to be carefully planned to avoid disrupting the work of the users. Talking about a maintenance phase therefore has meaning in both contexts. Other similarities between the structured and Agile approaches include:
- The development team is often larger than the maintenance team.
- The initial development is much shorter than the maintenance phase.
- The cost of changes is greater during the maintenance phase.
The increasing cost of maintaining legacy systems was exemplified by a UK government report from 2021 which reported that out of a total budget of £4.7BN, about half (£2.3BN) was spent “keeping the lights on”.
Definition
According to Gartner, a legacy system is “an information system that may be based on outdated technologies, but is critical to day-to-day operations”. The term legacy system is therefore relative - it does not indicate a system built in a particular style or using a particular technology; any system can become a legacy system over time as technology and functional requirements evolve.
Types of change
In 1976, Swanson identified the three types of software change shown below that might occur during maintenance. These categories have been widely adopted, although some authors have suggested alternative formulations based on the type of activity rather than on the intention behind the change (Chapin, 2001). All three types contribute to software evolution.
Corrective
- Processing failure
- Performance failure
- Implementation failure
Adaptive
- Change in data environment
- Change in processing environment
Perfective
- Processing inefficiency
- Performance enhancement
- Maintainability
Corrective changes are intrinsically linked to the accumulation of technical debt incurred during the development phase. Technical debt refers to the shortcuts and suboptimal solutions adopted to expedite delivery or reduce costs, often at the expense of code quality and maintainability. During initial development - especially in the later stages when there is pressure to release the first version of the application - these quick fixes and compromises accumulate, stocking up problems for the future.
Adaptive changes are intended to keep pace with changing requirements. The risk is that developers will be conservative when it comes to modifying the existing codebase and will prefer to add workarounds rather than carry out more extensive refactoring. Such an approach makes the codebase increasingly complex and harder to modify. This is sometimes referred to as architecture erosion since it gradually compromises any overarching architectural conventions.
Perfective changes are designed to add missing functionality to the application. In an Agile project, that could mean addressing some of the backlog items that were deemed low priority and were therefore not included in the initial release. Alternatively, they might be the result of post-release requests from the client on the basis of experience with the application and user feedback. They share the same risks as adaptive changes leading potentially to maintenance efforts becoming more time-consuming and costly as developers must navigate and address the accumulated technical debt to implement new features, fix bugs, or adapt to changing requirements. The ongoing management of technical debt is therefore crucial during the maintenance phase to ensure that the software remains functional, reliable, and scalable, ultimately supporting the system’s long-term evolution and reducing the risk of system degradation.
Lehman’s laws
Another body of theory that was developed in the 1970s and has been repeatedly validated since concerns the phenomenology of software evolution - i.e. rules that appear to hold true in most situations. The table below lists the eight laws of software evolution that were developed by Manny Lehman and Les Belady between 1974 and 1996 (Herraiz et al., 2013).
Table 1. Lehman’s laws (Herraiz et al. (2013))
| Number | Law |
|---|---|
| I | Law of Continuing Change A system must be continually adapted, or else it becomes progressively less satisfactory in use. |
| II | Law of Increasing Complexity As a system is changed, its complexity increases and becomes more difficult to evolve unless work is done to maintain or reduce the complexity. |
| III | Law of Self Regulation Global system evolution is feedback regulated. |
| IV | Law of Conservation of Organisational Stability The work rate of an organisation evolving a software system tends to be constant over the operational lifetime of that system or phases of that lifetime. |
| V | Law of Conservation of Familiarity In general, the incremental growth (growth rate trend) of systems is constrained by the need to maintain familiarity. |
| VI | Law of Continuing Growth The functional capability of systems must be continually enhanced to maintain user satisfaction over system lifetime. |
| VII | Law of Declining Quality Unless rigorously adapted and evolved to take into account changes in the operational environment, the quality of a system will appear to be declining. |
| VIII | Law of Feedback System System evolution processes are multilevel, multiloop, multiagent feedback systems. |
Note
Lehman’s laws refer to E-type (evolutionary) systems that approximate human activity in the real world in contrast to S-type (specified) systems which can be proven correct in terms of deterministic specification, and P-type (problem-solving) systems which apply heuristics or approximations to theoretical problems.
Over the years validation studies have been performed in different contexts to test the validity of Lehman’s laws. The results have been mixed; however, two of the laws (I and VI) have been validated in all cases. Change, therefore, is inevitable for all the reasons discussed above. This was clearly demonstrated in a study carried out in 2014 by Ramasubbu and Kemerer who tracked the changes to an example software system over time. As well as showing changes accumulating over time, they also revealed an interesting pattern in the way this occurred. The authors found that the functionality growth of a software system represented by “transactions” (similar to function points) followed an S-shaped pattern shown in Fig. 2. Once the system proves useful to early adopters, the demand for change exhibits a sudden increase or “takeoff”. After that, its cumulative functionality grows, following the sixth law of software evolution, until it reaches an inflection point. After this point in time, the growth rate of the software slows down until reaching the saturation point, where marginal functionalities are incorporated into the software baseline.
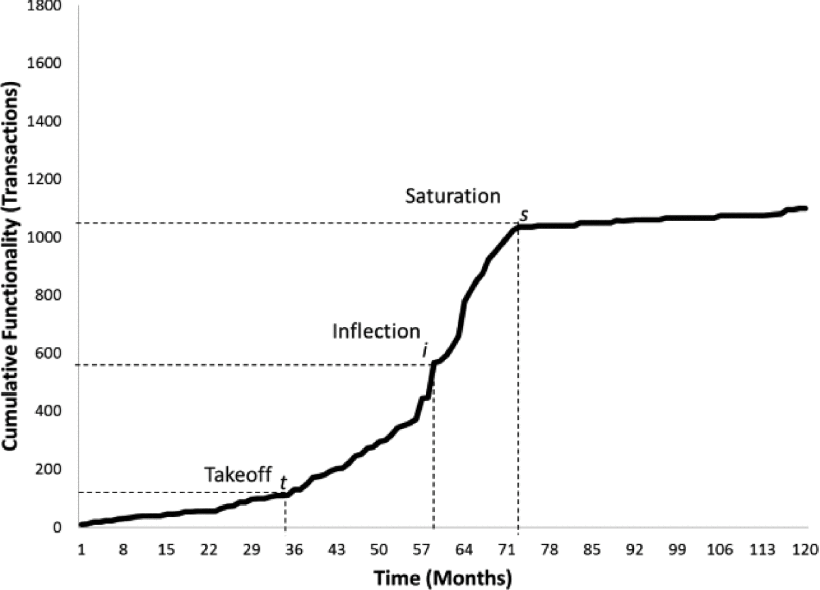
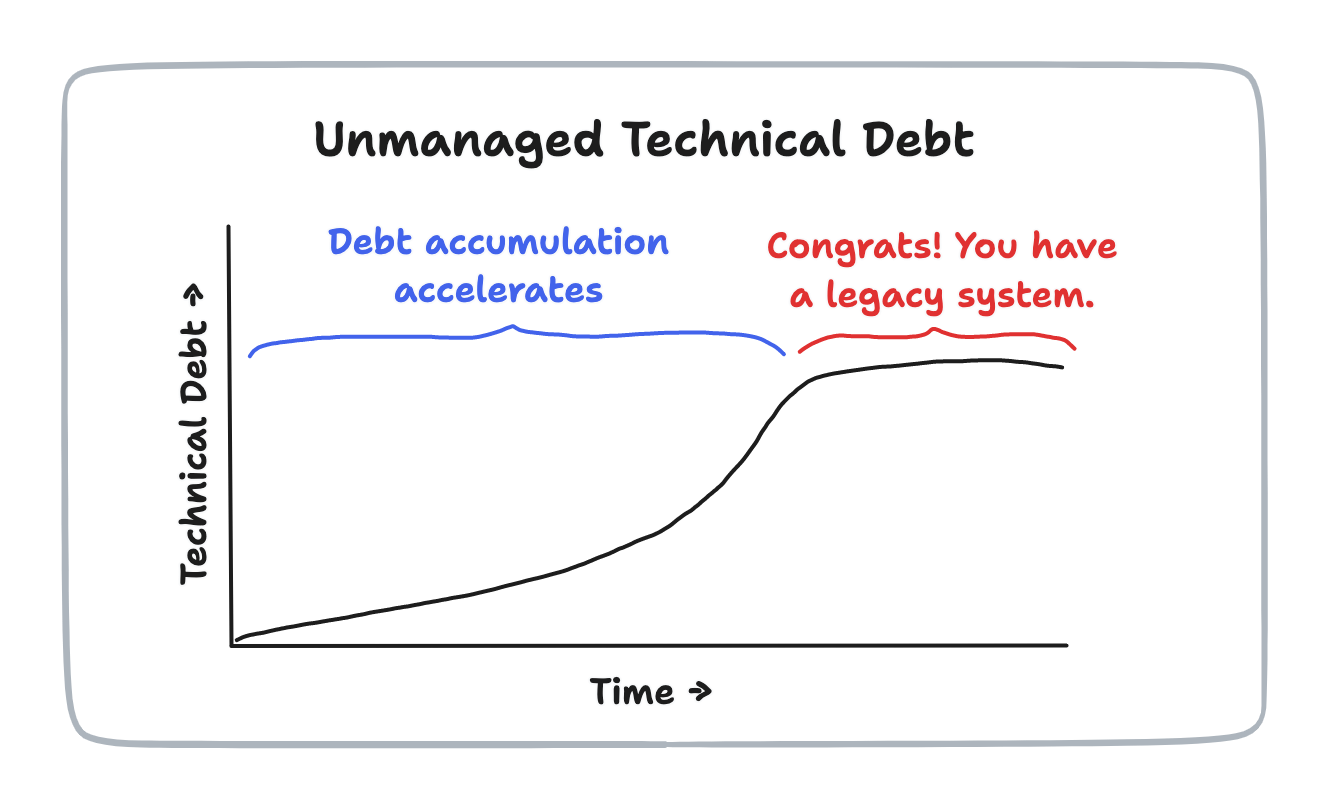
Once the rate of change has levelled out, the system is by definition receiving less attention. Over time, its technology will become outdated and members of the maintenance team will be lost through natural staff turnover. This has led some commentators to suggest that once the saturation point is reached, the system fits the description of a legacy system as shown in Fig. 3.
To examine the interactions between the laws, Franco et al. (2023) used the systems thinking approach to map the main concepts related to the software maintenance processes and describe their causal relationships. They expressed their finding through causal loop diagrams which correspond to mapping the causal relations between the system’s elements and which can be used to represent feedback loops of systems of any domain. The diagram consists of nodes and their relationships, where relationships can be positive or negative as indicated by the corresponding symbol at the end of a relationship arrow.
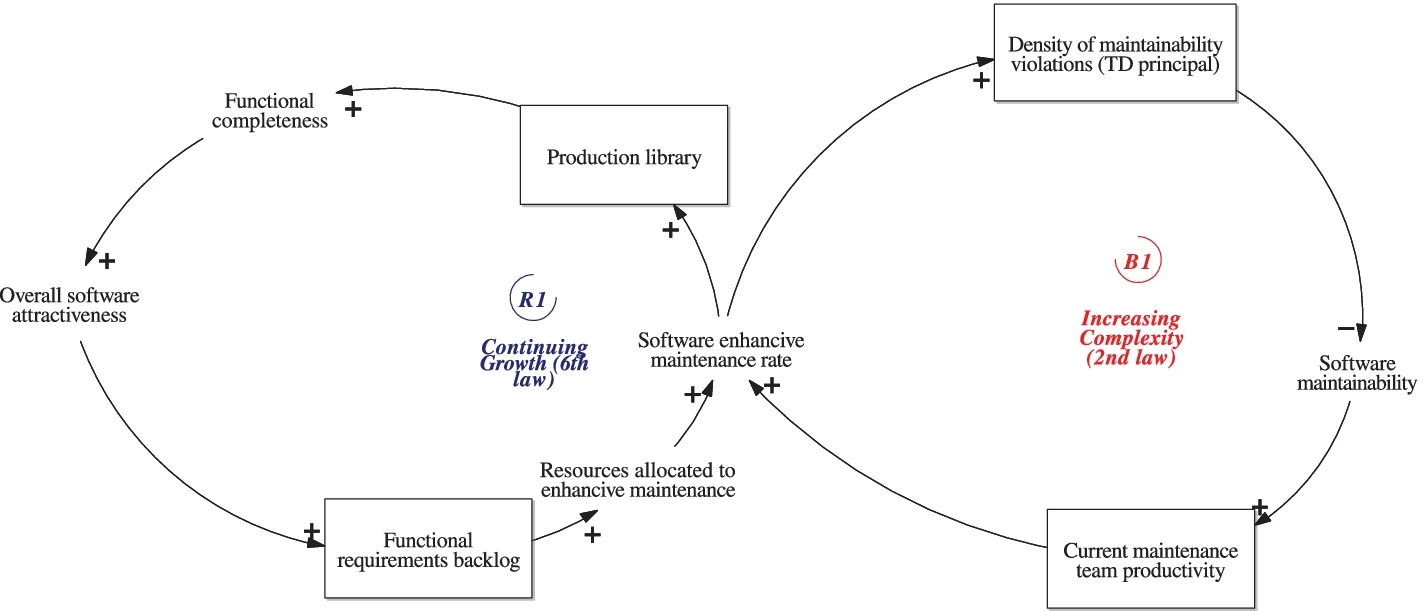
The left-hand side of Fig. 4 shows a positive feedback loop in which the more complete the system, the more attractive it is. It therefore garners more change requests and attracts more development resource. This positive feedback arises as a consequence of Lehman’s sixth law. The right-hand side shows a negative feedback loop arising from Lehman’s second law. As the rate of enhancive (perfective) changes increases as a result of user demand, technical debt increases. The consequence of this is that software maintainability decreases even though there is an apparent increase in development team productivity. This increase is “borrowed” against future maintenance effort. The two opposing feedback loops in Fig. 4 therefore limit the growth potential of the system in the long term. For a full development of the feedback model, please refer to the original article.
Evolution processes
The main message emerging from all of the theoretical work on software evolution is that software systems tend towards greater entropy over time just like physical systems. The term software entropy has been used to describe the gradual deterioration in a system’s quality, although a more common term is software rot. Lehman’s laws II and VII refer explicitly to the need for active management of technical debt during the evolution of a software system. This section examines some of the methods by which that can be achieved.
Service management
Bearing in mind that software evolution refers to the further development of an application after its initial release, the ITIL (Information Technology Infrastructure Library) framework provides a useful perspective. Aimed at large organisations, ITIL defines a set of structured processes and best practices for IT service management. The framework can be tailored for smaller organisations, but crucially it can be harmoniously integrated into an Agile software development environment for effective bug resolution and change request handling. In Agile, where flexibility and rapid iterations are key, ITIL’s Change Management process ensures that all changes, including bug fixes and new features, are systematically recorded, evaluated, and authorised, maintaining control and reducing risk. The Incident Management process complements Agile’s iterative cycles by quickly addressing and resolving bugs, ensuring minimal disruption to service. By incorporating ITIL’s structured approach within Agile’s dynamic framework, organisations can achieve a balanced blend of agility and control, enhancing responsiveness to change while maintaining service quality and stability.
Note
The latest version of ITIL does not define set processes, and instead refers to management practices to allow implementing organisations more freedom to define processes that suit their own context.
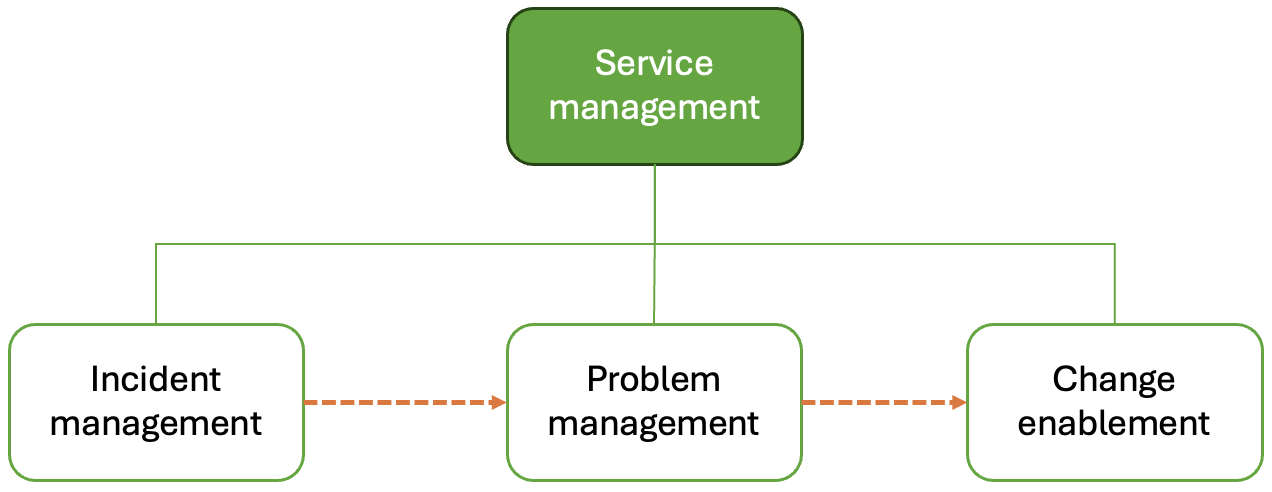
ITIL distinguishes between incidents, problems and requests for change (RFCs) which are variously handled by the management practices shown in Fig. 5. Incidents are interruptions to the IT service which could, for example, refer to bug reports coming through a helpdesk. It is the job of frontline support to resolve incidents as quickly as possible. A problem is the underlying cause of one or more incidents. Another responsibility of the support team is to identify and document workarounds for problems to help with the resolution of further incidents. Both incidents and problems can give rise to RFCs which are the items that are passed on to the development team for attention.
Impact analysis
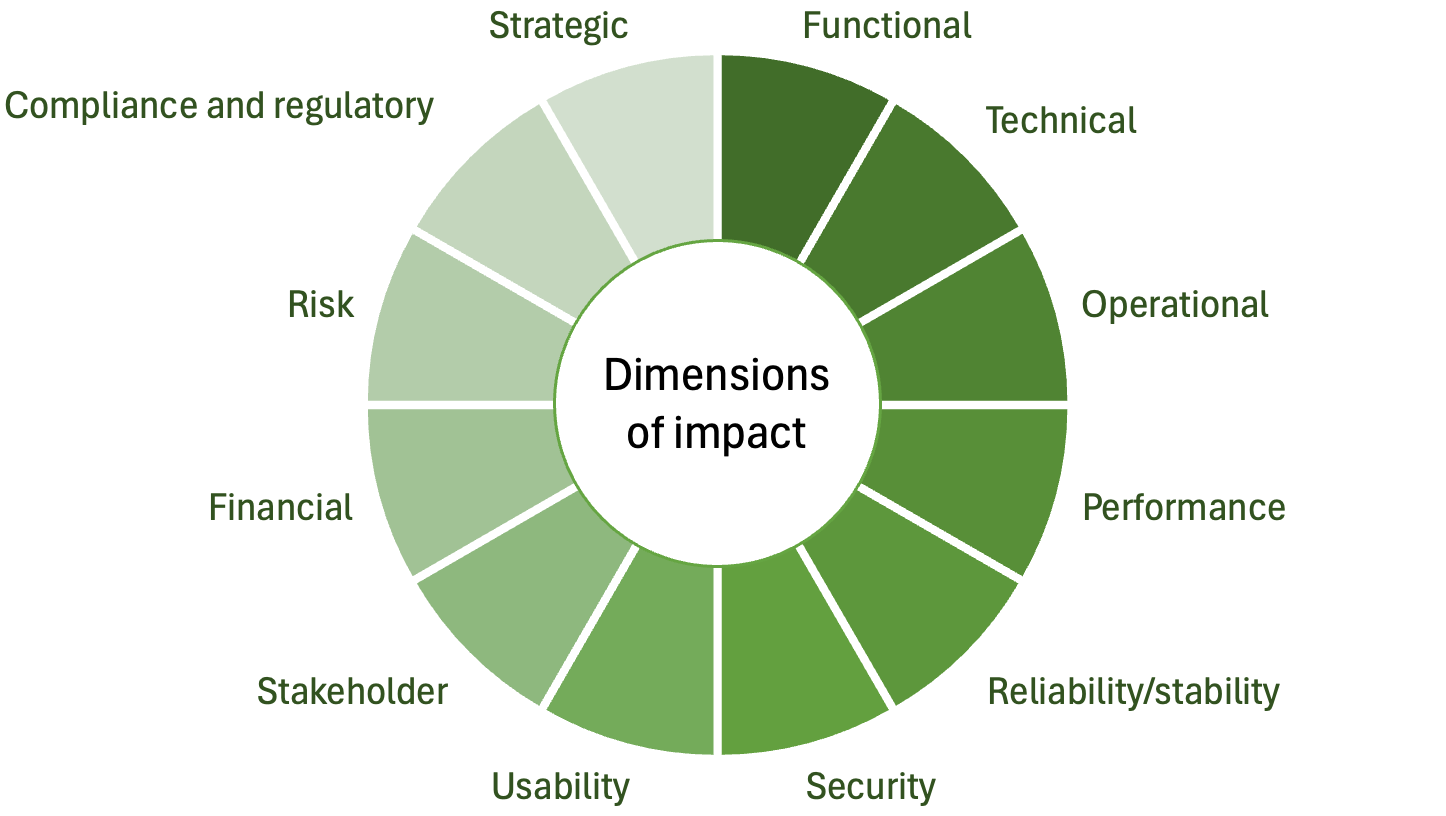
Impact analysis is a systematic process used to evaluate the potential consequences of proposed changes to the software system. This involves identifying the components, modules, and functionalities that may be affected by the change, assessing the risk of introducing new defects, and estimating the resources required for implementation. The primary goal of impact analysis is to understand the breadth and depth of the change’s effects, ensuring informed decision-making and effective planning. By thoroughly analysing the impact, developers and project managers can anticipate potential problems, mitigate risks, and ensure that changes are implemented smoothly without disrupting the overall functionality and stability of the software. Several types of impact can be identified, and it is useful to split the overall concept of impact analysis into different dimensions as illustrated in Fig. 6. You can use the grid below the figure to explore these dimensions in more detail.
Refactoring
We have already considered the use of refactoring software during the development process. During the maintenance phase, proactive use of refactoring systematically improves the internal structure of the code without altering its external behaviour. It allows the development team to clean up and optimise code to enhance readability, reduce complexity, and improve maintainability. Through refactoring, developers can address technical debt, remove redundancies, and simplify intricate code segments, making the software easier to understand and modify. As a result, refactoring helps maintain the software’s health over time, supports the seamless integration of new features, and facilitates ongoing adaptation to changing requirements and technologies. By investing in regular refactoring, organisations ensure that their software systems remain robust, agile, and capable of evolving efficiently to meet future business needs.
Earlier we discussed three types of change, corrective, adaptive and perfective. Given the imperative to pay down technical debt where possible, some authors have suggested a fourth category of preventative change. Despite the risk of introducing new bugs when modifying code, preventative tasks use refactoring to
- Clarify confusing code by adding comments or improving class, function and variable names
- Consolidate duplicated code to simplify maintenance
- Adjust code to accommodate future changes more easily
Bug-prone sections of code, often complicated or frequently modified, benefit significantly from refactoring to prevent future issues. Although refactoring requires careful consideration and testing to avoid replacing functional code with broken code, it ultimately leads to cleaner, more maintainable, and less error-prone software.
Re-engineering
Legacy systems pose some characteristic problems in terms of maintenance. As the definition above states, a legacy system is integral to ongoing operations. When a potential change to a legacy system is identified, several dimensions of impact take on particular importance. Changes to legacy systems are more expensive and risk-prone compared to more modern systems, for example. Retaining the system in its current form may not be compatible with the current organisational strategy and may expose the organisation to security vulnerabilities not present in current systems. When considering a change to a legacy system, therefore, the option to re-engineer the entire system must be considered. If the system ceases to deliver business value, another option might be to scrap it completely and migrate users to an alternative. Fig. 7. divides legacy systems into four clusters depending on their business value and system quality.
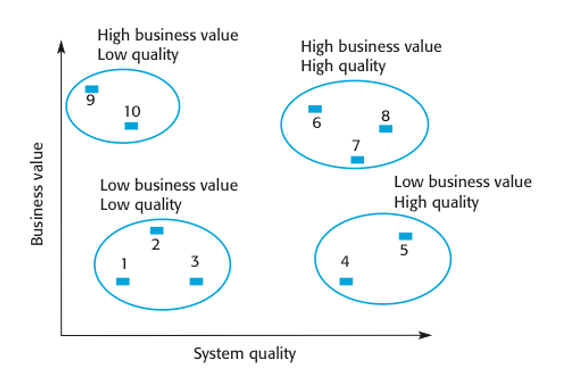
Classifying systems in this way suggests four different strategies:
| Business value | High | Re-engineer or replace | Maintain |
|---|---|---|---|
| Low | Scrap | Replace with COTS, scrap or maintain | |
| Low | High | ||
| System quality | |||
The need for software re-engineering became significant by the late 1990s, driven by the transition of information systems to web-based interfaces. Re-engineering emerged to address the challenges posed by legacy systems that are critical for business operations. Researchers have since developed flexible and repeatable process models and road maps for re-engineering these systems. According to Sommerville, software engineering encompasses all aspects of software production, from specification to maintenance. In contrast, re-engineering focuses on making legacy systems more maintainable by revisiting documentation, reorganising system architecture, and re-implementing the system using modern technologies while preserving core functionalities. Unlike forward engineering, which starts with a specification and moves towards implementation, re-engineering begins with an existing system and transforms it through understanding and modification. Re-engineering is necessary when code structures become unclear, documentation is missing, support for current hardware and software becomes obsolete, original developers are unavailable, and extensive modifications render the system difficult or expensive to change.
A key component of the re-engineering process is an initial activity aimed at understanding the existing system. When represented in process diagrams, it is the equivalent of requirements analysis in the forward engineering scenario. Although the existing codebase captures the structure and operation of the system, it is not necessarily easy to understand. This has led some authors to recommend the application of standard requirements analysis techniques during the system understanding phase. The term reverse engineering is often used to describe the process of analysing and understanding an existing software system to extract knowledge or design information from it. This process involves examining the system’s components, architecture, and behaviour to create a higher-level representation, such as models or documentation, which may not be available or may have become outdated over time. The goal of reverse engineering is to gain a comprehensive understanding of how the legacy system operates.
Once an abstract understanding of the legacy system has been developed, the next stage of the process is often referred to as transformation. The central concept is that the structure of the existing system is based on outdated conventions and needs to be redesigned using current techniques. Only after this transformation stage which may also include removing any unnecessary elements is the system ready for redevelopment.
It is worth mentioning that at the time of writing, a common theme in the literature is the migration of legacy systems to a microservices architecture which is deployed on a cloud service. However, further discussion of this particular case is beyond the scope of the module.