Table of Contents
Version Control
Version control is a fundamental practice in software development that allows teams and individuals to manage changes to code, track its history, and collaborate effectively. It provides a structured way to track changes, manage different versions of software, and coordinate the efforts of multiple developers. By maintaining a history of changes, version control helps developers understand who made modifications, when they were made, and why, making it easier to debug, refactor, or revert to previous versions if necessary.
The most widely used version control systems today, such as Git, Subversion (SVN), and Mercurial, allow for distributed collaboration, where each developer works independently on their own copy of the project. With tools like GitHub,GitLab, and Bitbucket, teams can easily manage branches, pull requests, and code reviews, ensuring that changes are properly reviewed and integrated into the main codebase.
Version control also plays a critical role in supporting continuous integration/continuous deployment (CI/CD) workflows by enabling automated testing and deployment pipelines. Whether working alone or in a large team, version control is an essential tool for maintaining the integrity of a codebase, managing collaboration, and ensuring that software can evolve efficiently over time.

Repositories
A code repository, or repo, is a centralised location where software project files and their version history are stored and managed. It serves as the backbone of version control systems, allowing multiple developers to collaborate on a project while keeping track of every change made over time. Developers save files to the repo through the commit action. A commit represents a snapshot of changes made to the codebase at a particular point in time. Each commit has a unique identifier (hash), and it typically includes a message describing the changes. Commits allow developers to track and review every modification made to the project over time.
A file version history is a detailed record of all the changes made to each file in a project over time. Every time a developer makes modifications and commits them, the system saves a snapshot of those changes, including the author of the change, the timestamp, and a message describing what was done. This history allows developers to track the evolution of the codebase, see who made specific changes, and understand why those changes were made.
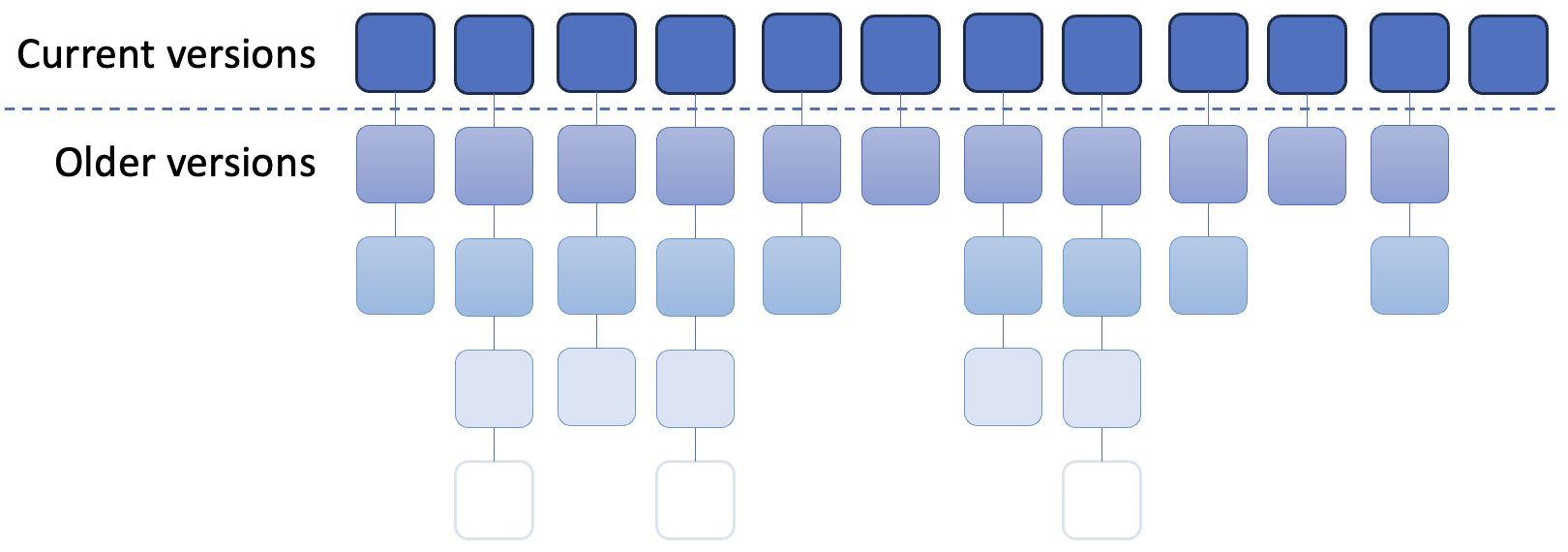
A major advantage of maintaining a full file history is that changes can always be undone. However, that is only possible for committed version of the file. Committing often is therefore a good practice to develop.
Distributed version control
In distributed version control systems such as Git, every developer has a full copy of the entire project history stored locally on their machine, rather than relying on a single, central server to manage the codebase. This means that all commits, branches and tags are available offline, and developers can work independently without needing continuous access to the central repository. Two key actions in distributed version control are forking and cloning. A fork is a personal copy of someone else’s repository, typically used in open-source development to create independent versions of a project that can be worked on and modified freely. A clone, on the other hand, refers to creating a local copy of a repository on your own machine, allowing you to make changes and later sync those with the original repository by pushing updates. In a collaborative project with mutiple developers, for example, each team member will clone the shared central repository so that their work does not interfere with anyone else’s.
While cloned repositories provide flexibility and independence, this strategy introduces certain logical challenges related to synchronisation and collaboration. Since multiple developers can work on the same project simultaneously, their local repositories may diverge over time, resulting in different sets of changes or conflicting modifications to the same files. For example, Fig. 3 shows three developers working on cloned copies of the shared central repository. They have each made their local copy at the same point in time. If Dev 1 finishes their work and commits new versions of files to the shared repository, Dev 2 and Dev 3 do not have those updates and are therefore working on outdated code.
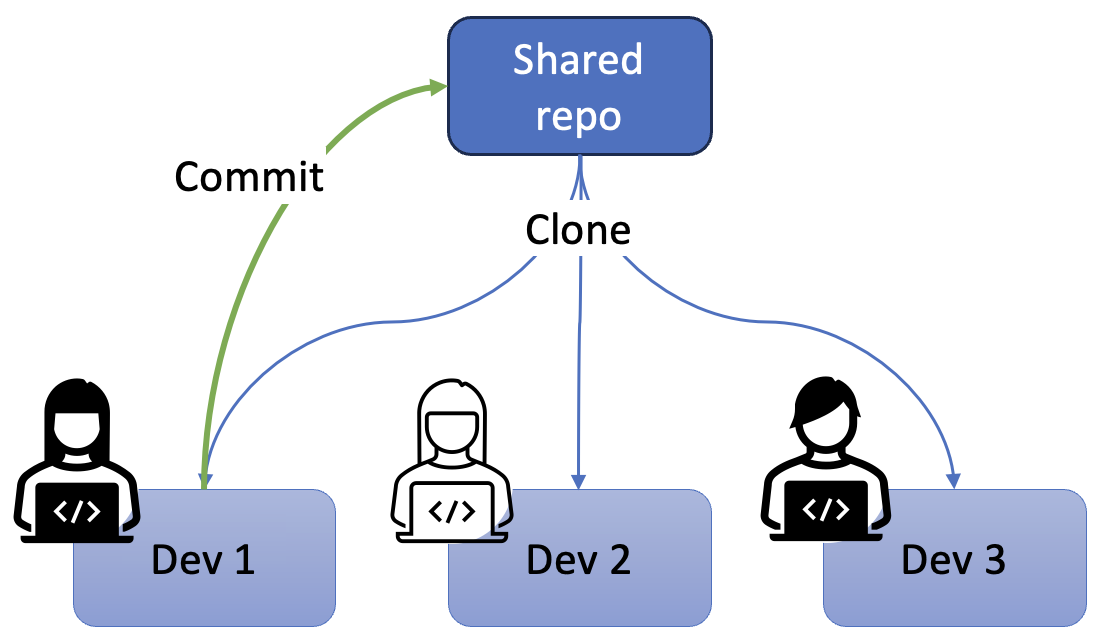
One major challenge is the need to synchronise the local clone with the remote repository to ensure that a developer’s work remains in sync with the broader team’s progress. If a developer doesn’t regularly pull updates from the remote repository, their local clone can become outdated, leading to potential conflicts when trying to merge changes. These conflicts occur when two or more developers modify the same section of code in different ways, requiring manual intervention to reconcile the differences.
Regular synchronisation through pulling and pushing updates helps avoid these issues. By frequently pulling changes from the remote repository, developers ensure that their local clone stays up to date with the latest work from other team members. This allows them to address conflicts earlier and maintain compatibility between their changes and the shared project. Without regular synchronisation, merging changes later can become more complicated, resulting in a more time-consuming and error-prone process.
Sensitive files
While the repository is the right place for code files, some files should never be shared.
The .gitignore file is an important configuration file used for protecting sensitive or
local information. It tells the version control system which files and directories should be
ignored and not tracked in the repository. The general purpose of this file is to prevent
unnecessary or sensitive files—such as temporary files, build artifacts, or local
configuration settings—from being included in version control, keeping the repository clean
and focused on source code and relevant resources.
One of the most crucial roles of the .gitignore file is to protect secret or environment-specific values. These may include sensitive information like API keys, passwords, database credentials, or private tokens that should never be exposed in the repository. Since version control systems like Git make every tracked file accessible to anyone with access to the repository, including secrets in the repository can lead to security risks, especially in public or shared repositories.
The .gitignore file prevents these secrets from being accidentally committed by specifying
the files that contain sensitive information (e.g., .env or config.json files).
Additionally, it helps manage environment-specific settings, such as local machine
configurations, that differ between development, testing, and production environments.
By ignoring these files, the repository remains consistent and secure across different
environments without leaking confidential data or unnecessary local configurations.
.gitignore example
Imagine you are working on a project where you store your API keys and database credentials
in a configuration file named .env like the example below:
1
2
3
4
5
6
# .env (this file should be ignored by Git)
API_KEY=abcd1234secretapikey
DB_USER=admin
DB_PASSWORD=supersecretpassword
DB_HOST=localhost
DB_PORT=5432
To protect these sensitive values, you would create a .gitignore file that tells Git to
ignore the .env file, preventing it from being added to the repository.
# .gitignore
# Ignore the .env file containing API keys and database credentials
.env
# Optionally ignore other config files with sensitive data
config/secrets.json
Steps to Implement
-
Create a .gitignore file: If your project doesn’t already have a
.gitignorefile, create one in the root of your repository. -
Add the sensitive files to .gitignore: Add the
.envfile and any other configuration files containing secrets (likesecrets.json,config.yaml, etc.) to the.gitignorefile, as shown above. This will prevent Git from tracking these files. -
Commit the .gitignore file: Commit the
.gitignorefile itself to the repository, so others working on the project know which files should be excluded from version control.1 2
git add .gitignore git commit -m "Add .gitignore to protect API keys and credentials"
-
Remove sensitive files if they were already committed: If the
.envfile or other sensitive files were already committed to the repository, remove them from Git history to ensure they are no longer tracked:1 2
git rm --cached .env git commit -m "Remove .env from repository"
Best Practice: Using Environment Variables
In addition to ignoring sensitive files in version control, it’s a best practice to use environment variables to load these values dynamically during runtime. This way, API keys and credentials stay outside the source code and can vary depending on the environment (development, testing, production).