Large language models
The use of large language models (LLMs) in software development is a relatively recent phenomenon but represents a significant leap in how software development and programming tasks are approached. They are a type of artificial neural network (ANN) that draws on developments in deep learning made during the 2010s. As ANNs grew more sophisticated, companies and researchers began to develop more specialised tools for software development. Early examples included autocomplete features in IDEs (Integrated Development Environments) which were based on simpler statistical models. The introduction of the transformer architecture by Google in 2017, through their paper Attention is All You Need, marked a significant advance. Transformer models, which use mechanisms called attention and self-attention, proved highly effective for a range of language processing tasks and became the backbone of modern LLMs.
OpenAI’s release of GPT (Generative Pre-trained Transformer) models started with GPT in 2018. These models demonstrated remarkable language generation capabilities, including generating coherent code snippets and understanding programming queries. Then in 2021, GitHub introduced Copilot, powered by OpenAI’s Codex (a descendant of GPT-3 specialised in programming languages), which provided context-aware code suggestions directly in the IDE. This represented a major step in operationalising LLMs for practical software development. Current tools go beyond code completion and also provide code explanation, bug fixing, and even writing entire programs based on natural language descriptions. Companies like Google, Facebook and Microsoft have also developed their own versions of AI-powered tools for coding.
The integration of LLMs in software development is expanding to include more aspects of software engineering, such as automated testing, code review, and even requirements analysis. The future likely holds more personalised and adaptive AI assistants that further streamline and enhance the developer experience. The rapid development of LLMs for software development reflects broader trends in AI and machine learning, highlighting the increasing convergence of software engineering and AI technologies. This evolution promises to make software development more efficient, accessible, and innovative.
Word embeddings
Word embeddings are a technique used in natural language processing (NLP) to represent words as vectors of real numbers. This method converts text into a format that computers can process more effectively, encoding semantic and syntactic aspects of words into high-dimensional space. Typically, each word is represented by a vector in a space with several hundred dimensions.
The fundamental idea behind word embeddings is to map each word to a vector such that words with similar meanings or those appearing in similar contexts have vectors that are close to each other in the embedding space. This not only captures the meanings of words but also their relationships, such as synonyms, antonyms, and various grammatical nuances.
For example, words like car and truck are semantically similar and thus have vectors that are close together in the vector space. Similarly, word embeddings can solve analogies by vector arithmetic, the classic example being king - man + woman = queen, illustrating how embeddings capture both semantic and relational information. Fig. 1 illustrates the vectors associated with ten words from the GloVe model. In this version, each vector has 100 dimensions (elements) which are colour-coded in the figure. From the visualisation it is possible to identify similarities between the vectors of related words.
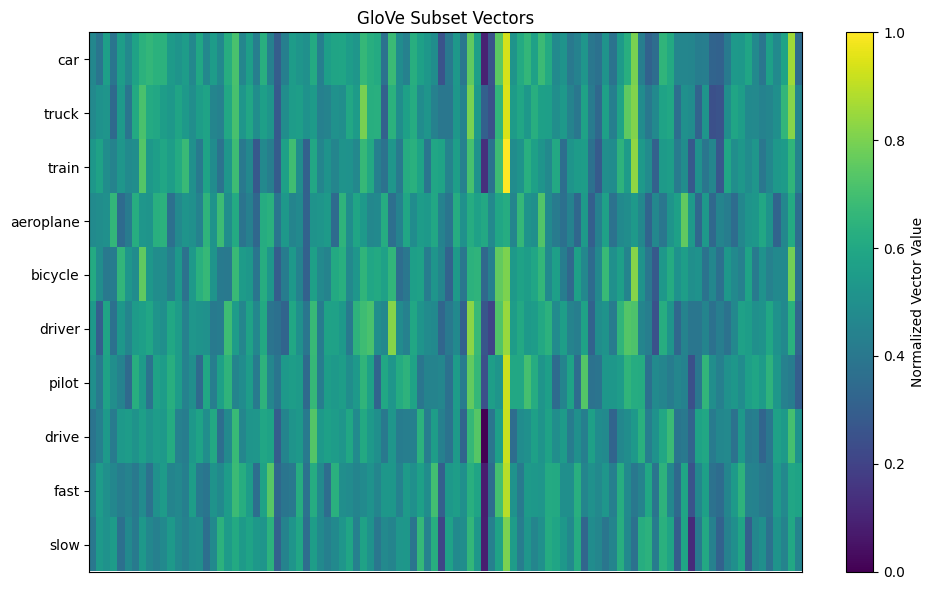
The vectors are constructed using algorithms that analyse words’ contexts in large corpora of text. Two popular methods are:
- Word2Vec: This technique, developed by Google, uses models like Skip-Gram and Continuous Bag of Words (CBOW). Skip-Gram predicts context words for a given target word, while CBOW predicts a target word based on its context. These models create embeddings by optimising them to predict words correctly given their contexts, thereby encoding the semantic information of words into the vectors.
- GloVe (Global Vectors for Word Representation): Developed at Stanford, GloVe constructs a large matrix that records how frequently pairs of words co-occur within a certain distance in the text. This matrix is then factorised to lower dimensions, effectively capturing the significant relationships between words in fewer dimensions. Each word’s vector is refined such that its dot product with another word’s vector approximates the log probability of their co-occurrence, enhancing the model’s ability to infer meanings and relationships.
The numerical values in a word vector are derived through the training process where the model iteratively adjusts the vectors to better fit the linguistic data. For instance, in Word2Vec, each word is initially assigned a random vector, and through training, these vectors are adjusted to maximise the likelihood of the actual word context in the data. The final numerical values of each vector are the parameters that result from this optimisation process.
Attention
The concept of attention is a fundamental innovation that enhances a model’s ability to process language in a nuanced and context-sensitive manner. Originating from the need to manage and interpret the relationships between elements in sequences of data, attention mechanisms provide a dynamic means of focusing on specific parts of data while considering the whole.
At its core, attention is a mechanism that allows a model to weigh and focus on different parts of the input data when performing tasks. This ability is crucial in language processing, where the relevance and meaning of words can significantly depend on the broader linguistic context.
In the context of LLMs, attention operates by assigning a relevance score to each part of the input data, which in language tasks, is typically a sequence of words or tokens. These scores determine how much ‘attention’ the model should pay to each part of the sequence when generating an output.
To illustrate the concept of attention, consider the sentence:
Despite the rain, the picnic by the river went ahead, surprising everyone with its success.
In this sentence, the attention mechanism would help a model to:
- Focus on Despite the rain: The model recognises that this phrase sets a contrasting context for the rest of the sentence. Attention allows the model to link this phrase with the outcome described later, surprising everyone with its success, illustrating how the initial adversity contrasts with the final outcome.
- Link picnic with by the river and went ahead: Attention helps the model identify that the location by the river is specifically associated with the picnic and that went ahead indicates the continuation of the picnic despite adverse conditions.
- Emphasise surprising everyone in relation to the entire event: The model uses attention to weigh the importance of the success being unexpected, tying it back to the initial mention of rain and the determination to proceed with the picnic.
This nuanced sentence showcases how attention mechanisms allow a language model to handle complex dependencies and contextual relationships within a sentence, enhancing its ability to generate sophisticated and contextually appropriate responses.
For example, in processing the sentence “The cat sat on the mat,” the model uses attention to determine that the words “cat” and “mat” have a strong contextual relationship, important for understanding the sentence structure and meaning.
The primary form of attention used in LLMs is called self-attention which allows the model to look at other words in the input sequence when processing a specific word. Self-attention is characterised by three main components:
-
Query, Key, and Value: Each word in the input sequence is transformed into three vectors: a query, a key, and a value. These vectors are generated through trainable linear transformations.
-
Scoring: The model calculates scores by comparing every query with every key. This comparison is typically performed through a dot product, and the scores determine how much each element in the sequence should influence the others.
-
Weighting and Summation: The scores are then normalised using a softmax function, which converts them into a probability distribution (weights). These weights are used to create a weighted sum of the value vectors, resulting in an output vector for each word. This output vector is a synthesis of relevant information from across the input sequence.
Prior to the advent of attention mechanisms, models like recurrent neural networks (RNNs) processed text sequentially, which made it difficult to maintain context over long distances. Attention, by contrast, processes all words at once, allowing it to capture relationships regardless of distance within the text.
Transformers
The transformer architecture, introduced by Vaswani et al. in the landmark paper Attention is All You Need in 2017, represents a significant breakthrough in machine learning, particularly in the field of NLP. The model is essentially built on several layers of attention mechanisms that process data simultaneously, unlike previous models that processed input sequentially. This architecture consists of two main parts: the encoder and the decoder. This structure is illustrated in Fig. 2 where the encoder part is shown on the left and the decoder on the right.
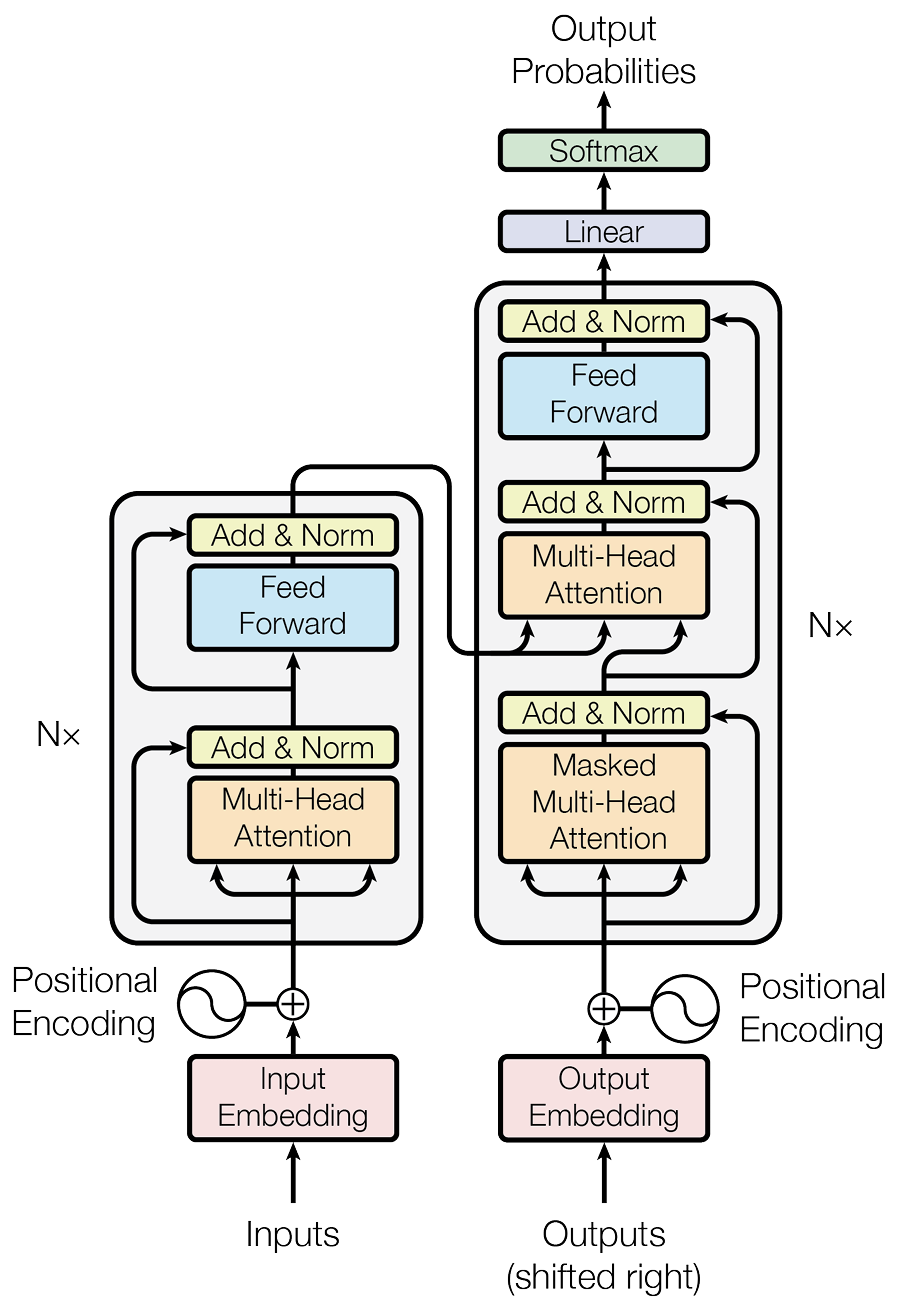
The Encoder
The encoder’s role is to transform input data into continuous representations that contain both the information of the individual elements and their context within the sequence. This is achieved through the following steps:
- Input Embedding: Each input token (word) is converted into a vector using an embedding layer. These embeddings incorporate positional encoding to maintain the sequence order, as the model itself does not inherently process data sequentially.
- Self-Attention Mechanism: The key innovation in the transformer is the self-attention mechanism in the encoder. Each input embedding is transformed into three vectors: queries, keys, and values. The model calculates attention scores by comparing all queries with all keys (using dot products), which are then used to weigh the values. This weighting process allows each output element of the encoder to consider the entire input sequence, emphasising parts of the sequence as needed.
- Feed-Forward Neural Networks: Each position’s output from the attention layer is fed into a feed-forward neural network, which is applied identically to all positions. This layer further transforms the data, ensuring complex patterns can be learned.
- Residual Connection and Layer Normalisation: After each attention and feed-forward layer, a residual connection is added (the input to the layer is added to its output), followed by layer normalisation. This helps in mitigating the vanishing gradient problem and promotes faster training.
The Decoder
The decoder is designed to output one token at a time, for tasks such as translation or text generation, and works in a similar way to the encoder but with some key differences:
- Masked Self-Attention: The first layer of the decoder is a masked self-attention layer, which prevents positions from attending to subsequent positions. This masking ensures that the predictions for a given position can only depend on known outputs at earlier positions.
- Encoder-Decoder Attention: In addition to the self-attention layers, the decoder includes encoder-decoder attention layers. These layers help the decoder focus on relevant parts of the input sentence, similar to how attention works in sequence-to-sequence models with attention.
- Output Layer: Finally, the decoder’s output is transformed into predicted tokens one step at a time. Each output token is fed back into the decoder during the next step of generation, in a process known as auto-regressive generation.
Transformers have proven to be highly effective for a range of tasks beyond NLP, including computer vision and music generation. The architecture’s ability to handle parallel computations has drastically reduced training times and improved the handling of long-range dependencies in sequence data. Furthermore, transformers have paved the way for the development of large-scale models such as BERT, GPT and others, which have set new benchmarks across various machine learning tasks. The scalability and efficiency of transformers make them a pivotal development in the AI field.
Attention and word embeddings
In transformer models, the process typically starts with word embeddings as the initial input, which offer a basic, context-neutral representation of the words in a sentence. Attention mechanisms build upon these static embeddings to create dynamic, context-sensitive representations. For instance, in a sentence like “The bank of the river is steep”, the attention mechanism enables the model to focus more on river, helping to clarify that bank relates to the riverbank rather than a financial institution.
The integration of word embeddings with attention mechanisms enhances the model’s ability to process text by enabling it to adjust how words are represented based on their context. This adjustment is crucial for tasks that require a detailed representation of text, such as sentiment analysis, where the connotation of a word can significantly alter depending on the context it is used in.
In more complex models, attention is applied in multiple layers, iteratively refining these representations. Multi-layered attention helps the model to represent complex language structures and relationships within the text more effectively, improving its ability to process intricate patterns and dependencies without the implication of human-like understanding.
Training
Preparing an LLM typically involves several methodical steps, starting with generalised pre-training, followed by fine-tuning, and concluding with prompt processing. These stages are designed to equip the model with a broad capability to process language and to specialise it for specific tasks.
The initial stage in preparing an LLM is generalised pre-training, where the model is trained on a vast and diverse corpus of text. This corpus might include books, articles, websites, and other forms of written content, covering a wide range of topics, styles, and structures. During pre-training, the model engages in tasks such as predicting the next word in sentences or filling in blanks within texts (masked language modelling). This phase is crucial as it helps the model develop a base layer of linguistic patterns and data relationships, which are essential for generating and processing text in a human-like manner.
After pre-training, the model undergoes fine-tuning, which adjusts its parameters to enhance performance on specific tasks or within particular domains. This involves training the model on a smaller, task-specific dataset that reflects the challenges the model will address in practice. For instance, if the LLM is intended for use in medical diagnostics, it would be fine-tuned on medical journals, patient records, and other relevant texts. Fine-tuning allows the model to align more closely with the specific vocabulary and data patterns of the target field, improving its output relevance and accuracy.
The final preparation stage is prompt processing, which involves crafting and refining prompts that guide the model to generate desired outputs. A prompt is essentially a query or an instruction that directs the model’s response generation process. Creating effective prompts is crucial, requiring a strategic approach to determine how the model responds to various inputs. This stage may involve experimenting with different prompt formulations to identify which elicit the most accurate and contextually appropriate outputs. Techniques such as few-shot learning can also be incorporated, where the model is provided with a few examples within the prompt itself, aiding in adjusting its response mechanisms for the task without extensive additional training.
The preparation of an LLM involves comprehensive steps that ensure the model is equipped with a broad capability to generate and process language and is specifically tailored to perform a wide range of linguistic tasks. Through careful pre-training, precise fine-tuning, and strategic prompt processing, an LLM can be effectively prepared to tackle everything from simple text generation to complex problem-solving across various domains.
Examples
Since the release of the first version of OpenAI’s GPT there has been a great deal of development in the area of LLMs and several have been designed specifically to generate source code rather than natural language. Notable examples include:
-
OpenAI’s Codex
An adaptation of the GPT-3.5 architecture, Codex is specifically trained on a mixture of licensed data, data created by human trainers, and publicly available data in multiple languages to generate and understand code. It powers applications like GitHub Copilot.
-
GitHub Copilot
While Copilot itself is not a language model, it’s a tool powered by OpenAI’s Codex. Integrated with Visual Studio Code, it assists developers by suggesting entire lines or blocks of code, helping them to write code faster and with fewer errors.
-
Google’s BERT for Code Search
While BERT (Bidirectional Encoder Representations from Transformers) was initially designed for natural language understanding, variants of BERT have been adapted to understand code semantics, especially for tasks like code search.
-
Facebook Aroma code-to-code search and recommendation tool
Aroma is a tool by Facebook that leverages neural networks for code-to-code search and recommendation, helping developers find and use code snippets from a large-scale codebase.
-
Powered by GPT-3 and Codex, TabNine is an AI-powered code completion tool. Though it’s not exclusively a language model, the underlying AI aids in predictive code completion.
-
Uses deep learning to analyse and learn from code repositories. While not exclusively for code generation, it assists in code reviews by pointing out potential issues.
At the time of writing, these are not the only software engineering tools and services to make use of generative AI, and there will be many others in the near future.
Claude Code
Claude Code is an AI-powered development tool that integrates LLM capabilities directly into the software development workflow. Unlike simple code completion tools, Claude Code provides comprehensive assistance throughout the development process, from planning and implementation to testing and documentation. It represents a significant evolution in how LLMs can support software engineering tasks, offering capabilities that extend far beyond line-by-line code suggestions.
Integration and accessibility is a key strength of Claude Code. It integrates with popular development environments including VS Code, JetBrains IDEs (such as IntelliJ IDEA and PyCharm), and can be accessed through both command-line interfaces and web browsers. This flexibility allows developers to choose the interface that best suits their current task — terminal sessions for operations requiring git integration, and web sessions for cleaner review and reasoning tasks. Some developers maintain multiple parallel sessions to handle independent tasks simultaneously, maximising throughput without waiting for sequential operations to complete.
A distinctive feature is plan mode, which encourages developers to outline their approach before writing code. In plan mode, you describe the functionality you want to implement, and Claude helps break it down into manageable steps, suggests appropriate algorithms, and generates preliminary code structures. This approach mirrors professional software engineering practices where planning precedes implementation, helping to ensure that the final solution is well-structured and addresses all requirements. Plan mode is particularly valuable for complex tasks where multiple valid approaches exist, as it allows you to evaluate options before committing to an implementation.
Customisation through project memory is achieved using a CLAUDE.md file maintained in your project repository. This file acts as a living style guide and project memory, capturing team conventions, common mistakes to avoid, preferred coding patterns, and project-specific commands. When Claude gets something wrong or deviates from your preferences, you update CLAUDE.md to prevent similar issues in future interactions. This file typically includes sections on coding style, workflow preferences, debugging approaches, and testing requirements. By keeping this file concise and focused, you create a persistent knowledge base that improves the quality of assistance over time.
An important principle when working with Claude Code is to build verification into your workflow. Rather than simply accepting generated code, establish ways for Claude to verify its own work. This might involve running test suites, executing specific commands to check functionality, or reviewing outputs against expected results. For example, after implementing a new feature, Claude can be instructed to run relevant tests and interpret the results, iterating on the solution if issues are discovered. This verification loop significantly improves code quality and reduces the likelihood of undetected errors. The ability to verify outputs transforms Claude from a code generator into a more reliable development partner.
For recurring tasks, Claude Code supports custom slash commands that can be shared across your team. These commands encapsulate common workflows — such as preparing clean commits, running test suites, or generating documentation — reducing friction and ensuring consistency. Similarly, you can pre-authorise safe tools and commands through permission settings, balancing security with workflow efficiency. As you become more proficient, you might explore advanced features like subagents for specialised tasks, hooks that automatically format code after edits, or MCP (Model Context Protocol) integrations that connect Claude to external systems like issue trackers or analytics platforms.
The effectiveness of Claude Code depends significantly on how it’s used. Providing clear context, maintaining project memory through CLAUDE.md, incorporating verification steps, and iterating on your workflows all contribute to better outcomes. As with any AI tool, the results reflect the patterns present in training data, meaning Claude performs best on well-documented problems and established patterns. Understanding these capabilities and limitations helps you leverage Claude Code effectively while maintaining appropriate oversight of the code it generates.
Limitations
The transformer architecture faces several drawbacks, including a high computational cost. This cost escalates quadratically with sequence length due to the attention mechanism, which needs to consider the entire input sequence, complicating the model’s interpretation and debugging. Additionally, transformers and other ANNs are prone to overfitting when fine-tuned with limited task-specific data. A general limitation across ANNs is their inability to create new information or ideas; they can only synthesise responses based on patterns learned from their training data. This reliance on training data means that solutions generated by LLMs often reflect the most common methods and styles present in that data. While LLMs typically perform well when generating solutions for well-documented problems with ample examples in the training set, they struggle with obscure or uncommon issues, sometimes leading to inaccurate outputs. In extreme cases, where training data is sparse or non-existent, LLMs may resort to making best-guess assumptions — often inaccurately — resulting in what is known as “hallucination.” The novelty of the problem significantly increases the likelihood of hallucinations, highlighting a critical limitation in the current capabilities of LLMs and ANNs.